

Demasiada información no es control, es desinformación
Hace unos años, participé en el desarrollo de un proyecto piloto consistente en crear un producto desde cero, partiendo de una supuesta solución ante un determinado problema y orientado a un nicho muy concreto, aprovechamos algunos nuevos conceptos y metodología de diseño de productos que algunos compañeros habían aprendido, nos pusimos manos a la obra y a poner en práctica aquellas lecciones que más adelante pasaron a ser nuestras también.
Entre estas metodologías para empezar a pensar en un producto viable, se encontraba uno bastante conocido llamado «Design Thinking» y basándonos en este sistema elaboramos una serie de características para un nuevo producto que, de no haber utilizado este sistema, y basándonos únicamente en nuestra experiencia y conocimientos, hubiera sido muy diferente.
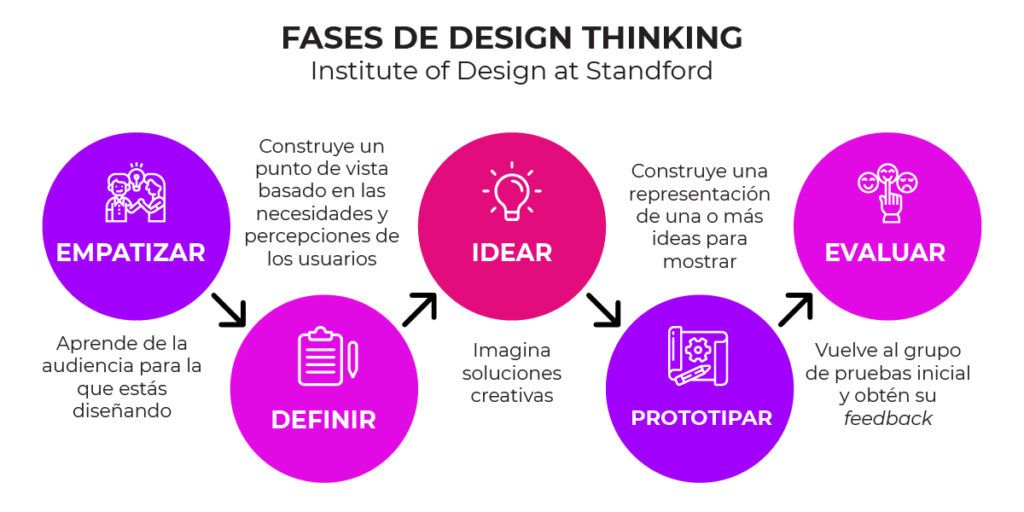
El resultado, años después, fue un software bastante bueno, utilizado por muchas empresas de todo el país y con una cuota de mercado mucho más grande de la que imaginábamos en un principio cualquiera de los que participamos en el desarrollo (tanto a nivel de programación, como comercialmente, y como a nivel de gestión y control). El uso de una metodología como Design Thinking nos enseñó a discernir entre «lo que nosotros creemos importante desarrollar» frente a lo que «el usuario considera importante».
Esta diferencia la he visto antes y después en elementos y características de otros productos y debo decir que ha sido una constante, ya que productos y herramientas que no utilizan este sistema tienen un enfoque muy «técnico» o muy «personal» llevando al desarrollo de ciertas características que nos puede parecer vitales o super-importantes y que realmente el usuario que lo vaya a utilizar apenas le interesa, o todo lo contrario… le interesa pero apenas con la profundidad que esperaba.
Ejemplo de esto que comento es una característica que seguramente os suena: la información de depuración.
Alguien quiere un software para gestionar un servidor y cuando lo desarrollamos nos centramos en extraer toda la información posible, almacenarla en enormes tablas y bases de datos para que, llegado un momento determinado, el usuario pueda obtener cualquier información que pueda necesitar.

Como técnicos y más concretamente como personal de sistemas, solemos estar acostumbrados a guardar logs de todo: llamadas, uso del procesador, memoria, disco duro, cantidad de información leída, escrita, número de hilos, número de procesos, recursos de cada proceso, destinos de llamadas, cuantas llamadas por minuto, y un larguísimo etcétera que se encarga de llenarnos el espacio de disco duro de información que «puede» que algún día nos sea necesaria.
Si nuestro sistema tiene algún problema, nos alegramos de tenerlo todo guardado, poder sacar gráficas, estadísticas, analizar estos datos y descubrir por qué un proceso ha caído sin ningún motivo aparente pero que, coincidiendo con el elevado y puntual aumento del número de INSERTS en la base de datos, podemos elaborar una teoría consistente en que, cuando se escribe bastante en la base de datos, la aplicación deja de funcionar.
No obstante, cuando un sistema está en producción y el comportamiento se considera «estable», esta cantidad de información se sigue almacenando, pero pasamos a un sistema paranoico basado en crear alertas por cualquier evento que nos pueda generar cualquier tipo de incertidumbre. ¿Qué pasa si el procesador está por encima del 60%? Quiero que me mande una alerta! ¿Qué ocurre si hay un porcentaje de llamadas no contestadas en la última hora? Quiero que me mande una alerta! ¿Qué ocurre si recibimos más de N peticiones HTTP a la web en menos de N minutos? Quiero que me mande una alerta!
Cuando todo esto se asocia a un producto software, pasamos a tener un software genera alertas por cualquier circunstancia y es entonces cuando nos empezamos a acostumbrar a recibir alertas, bajando nuestro nivel de atención ante lo que puede ocurrir que sí es importante.
Se entiende que la capacidad de monitorizar los recursos en un sistema de comunicaciones hasta el infinito puede ser un elemento diferenciador de cara a conseguir usuarios que estén interesados en monitorizar estas características pero ¿y aquellos a los que no les interesa? ¿Realmente es necesario generar gigas de información cuando el usuario no tiene el más mínimo interés o peor aún… no entiende qué es lo que se está informando?
Somos conscientes que hay que disponer de una importante cantidad de datos de alta calidad para poder tomar ciertas decisiones, de ahí la importancia de saber «reducir» la ingente información que somos capaces de almacenar, en información de calidad que realmente sirva para esa toma de decisiones.
Pero también es importante de cara a desarrollar productos, entender quién es el objetivo de nuestro desarrollo, el usuario al que va destinado el producto y entender que esa información, más que ayudarle, le está perjudicando en la adaptación. Los desarrolladores solemos cometer varios fallos importantes, considerando que «lo que a nosotros nos interesa, también le interesa al usuario» y por esta razón, creamos opciones, botones, parámetros incomprensibles que a nosotros como desarrolladores nos llevará un tiempo considerable en configurar, y que al usuario jamás le interesará tocar por que, o bien no entiende cómo funciona, o bien necesita otra información más importante.
En resumen, los programadores debemos aprender que lo que nosotros creemos que es importante, para quien va a utilizar la aplicación, no tiene por qué serlo. De ahí la importancia de contar con otras personas, compañeros que tienen más trato con los usuarios y que sean capaces de hacernos ver qué es realmente lo que el usuario necesita.
Manejar una ingente cantidad de información nos da el control completo del sistema, pero ese control se vuelve inútil cuando esta información nos bombardea constantemente de alertas que, llegado el momento, no nos sirve para nada ya que las verdaderas alertas importantes y que hay que tener en cuenta, se hallan entre 40 o 50 alertas que de nada sirven.


